Audio Clip
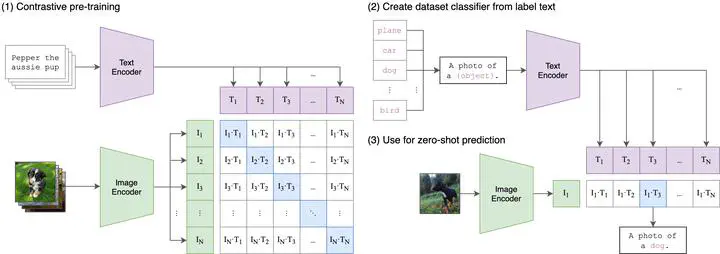 Photo by rawpixel on Unsplash
Photo by rawpixel on Unsplash
In recent years, the development of multimodal learning models such as OpenAI’s CLIP has significantly improved the understanding and generation of images and their associated textual descriptions. Inspired by the success of CLIP in the vision-language domain, we propose a novel approach called Contrastive Language-Audio Pretraining, which aims to learn the relationship between audio data and textual descriptions.
In this project, we replace the image data in the CLIP model with audio data and train the model using a large dataset of audio clips with corresponding textual descriptions. The objective is to develop a multimodal model that can effectively understand and generate audio and their associated textual descriptions.
ChengXing Xie
Artificial Intelligence Student
My research interests include LLM Agents, Multi-Modeling (VLMs, Diffusion).
{kind=link}